Kubernetes Tuning 2: CPU Limitlerini Kaldırarak Throttling Önlemek

Kubernetes resource limitleri, podların aşırı kaynak tüketimlerini sınırlayarak kaynak yetersizliğini önlemeye ve her bir podun sadece kendi limitleri dahilinde çalışabilmesini garantiler. Peki bu verimli bir yöntem mi? Ya performans olarak limitler faydasından daha çok zararlıysa? Bu yazıda tuning serüvenine limitleri ele alarak bu sorulara cevap veriyoruz.
Podlara, resource request ve limitleri tanımlayarak onların ihtiyaç duydukları CPU ve memory kaynaklarını elde etmelerini ve belirlenen limitleri geçmemek kaydıyla çalışabilmelerini sağlıyoruz.
Birçok best practice makalesinde de resource request ve limitlerin önemine dair yazılar okumuşsunuzdur. Bir süre öncesine kadar bizde benzer şekilde limitlerimizi tanımlayarak ortamlarımızı emniyete aldığımızı düşünüyorduk. Ta ki şu tweeti görene kadar:
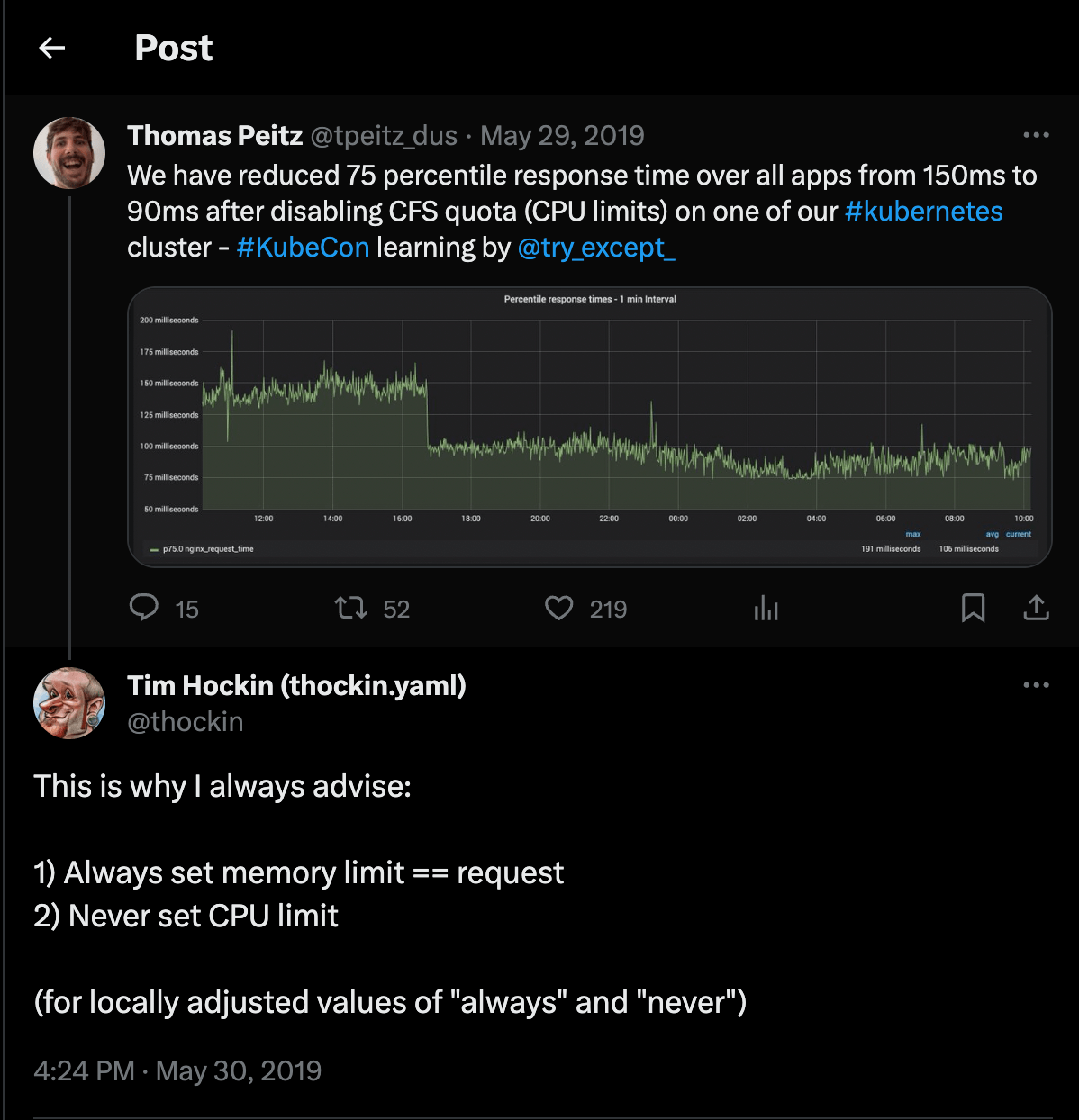
Kubernetes projesinin kurucularından olan Tim Hockin, CPU limitlerini kaldırdıktan sonra response time değerlerinde %75 olumlu yönde düşüş yaşadığını söyleyen bir kullanıcıya, oldukça net bir şekilde CPU limitlerinin kullanılmaması gerektiğine dair bir yanıt veriyor.
Bu o kadar ilgimi çekti ki, CPU limitlerine dair yaptığım deneyim aramalarında "For the Love of God, Stop Using CPU Limits on Kubernetes", "Stop CPU Limits" gibi ilginç başlıklara dahi rastladım 😅
Testlere ve gözlemlere geçmeden önce okuduğum makalelerde neden CPU limit olmaması gerektiği savını, çölde susuz kalan İsmet ve Özlem üzerinden diğer senaryolarla karşılaştırarak özetlemek istiyorum:
Her iki kişininde çölde hayatta kalabilmesi için günlük 1 litre su içmeleri gerekiyor ve günlük 3 litre su üreten kaynakları var. Hadi senaryolara bakalım:
- Request yok, Limit yok: Bu durum, her yeni Kubernetes kullanıcısının yaptığı gibi podlarda izlediği en kötü kaynak yönetim stratejisidir. Örneğimizde İsmet, Özlem'in ihtiyaç duyduğu 1 litre su da dahil olmak üzere tüm suları içerek Özlem'in ölmesine sebep oldu. Çünkü İsmet 3 litre suyu kendi içti ve ortada su kaynağı kalmadı.
- Request var, Limit var: Tüm best practice yazılarında gördüğümüz ve hepimizin uyguladığı stratejinin ta kendisi. Request sayesinde İsmet ve Özlem ihtiyaçları olan 1 litre suları aldılar ve hayatta kaldılar. Fakat bir gün Özlem hastalanır ve iyileşmesi için 1 litre daha suya ihtiyaç duyarsa, konulan 1 litrelik limit yüzünden o suya erişemeyecek. Halbuki daha ortada bir litre boşta duran su var. İşte bu sorunumuzun kaynağı ve daha detaylı konuşacağız.
- Request var, Limit yok: Bu ise birazdan deneyeceğimiz senaryo. Yukarıdaki örnekte olduğu gibi her ikisi de request sayesinde 1 litre sularını aldılar ve hayatta kaldılar. Özlem hastalanıp iyileşmesi için 1 litre daha su istediğinde, bu sefer bir limit olmadığı için ortada boşta kalan 1 litre suyu alacak ve hayatta kalacak.
İşte tüm olayın ve yazılan onca makalenin özeti bu şekilde. Fakat tüm bunları metriklerle ve testlerimizle göstermeye çalışalım.
CPU Throttling'e Uğrayan Podları Tespit Etmek
Yukarıdaki hikaye kulağa mantıklı geliyor. Peki gerçekten podlarımız ihtiyaç duyduğu halde ortada boşta duran kaynaklara erişemiyorlar mı? Hadi bunu öğrenelim.
Bu sorunun cevabını merak ettiğimiz için biz de hemen Prometheus ve Grafana ekranlarımızı açtık ve podlarımızın throttling değerlerini sorgulamaya başladık. Bunun için şu sorguyu kullanarak önce throttlinge uğrayan podlarımız var mı görelim istedik:
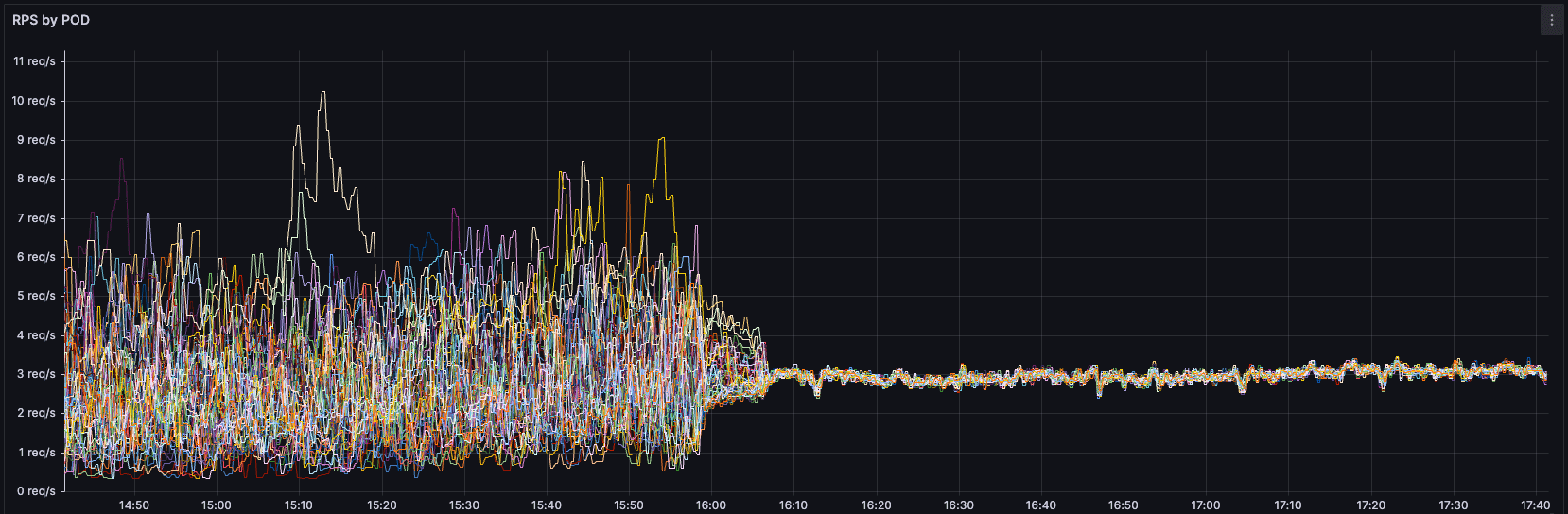
sum(increase(container_cpu_cfs_throttled_periods_total{namespace="prod", container="application"}[2m])) by (pod) / sum(increase(container_cpu_cfs_periods_total{namespace="prod", container="application"}[2m])) by (pod)Sonuçlar gerçekten şaşırtıcıydı. Sürekli bir CPU kısıtlamasına uğrayan podlarımızın sayısı çok fazlaydı. Yani bu podların işlemlerini daha iyi yapabilmeleri için CPU ihtiyaçları vardı fakat biz kaynak olmasına rağmen vermiyorduk.
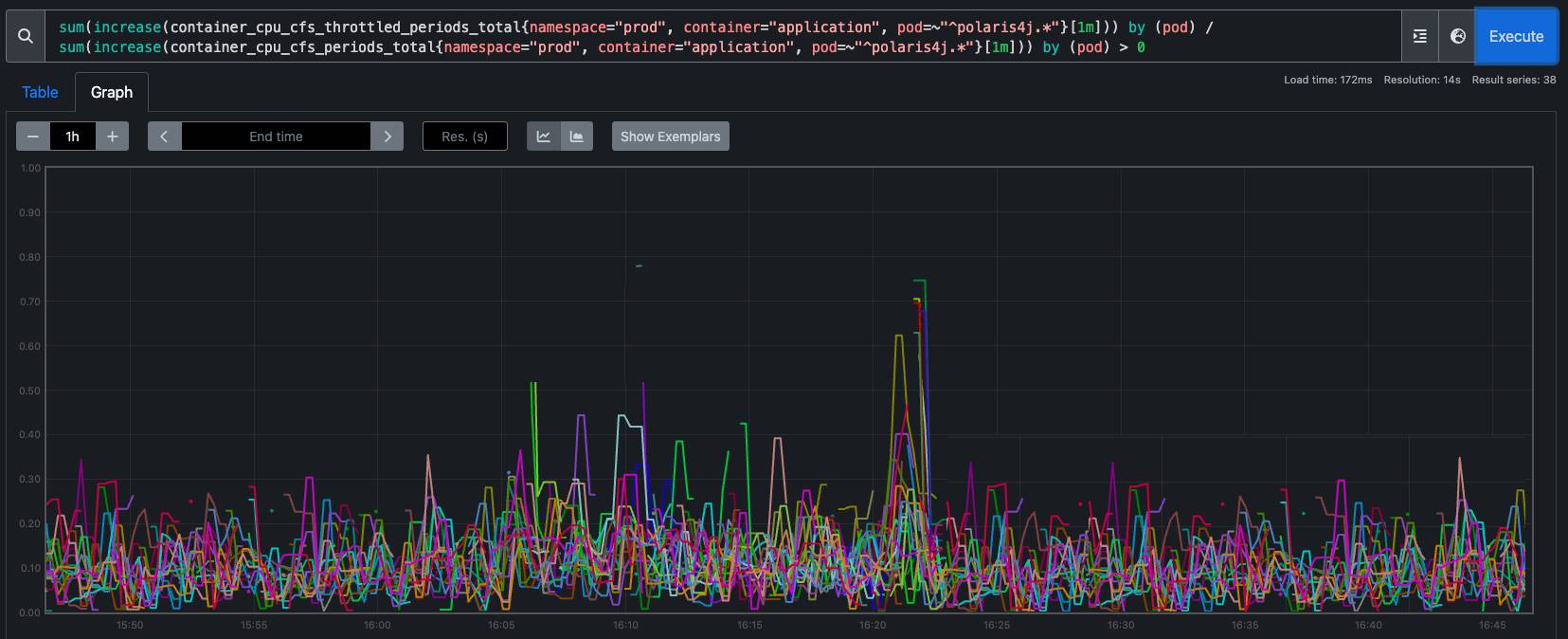
Tabi bu sorguya podların CPU limitlerini de katarak ne durumda olduklarını görmeye çalıştık. Yukarıda kısıtlamaya uğrayan podları K8S Grafana resource panelimizde de incelediğimizde daha şaşırtıcı sonuçlar gördük.

Örneğin bu pod, 2core request, 2core limit değerlerine sahip ve ortalama 0.5core bir CPU kullanımı var. Fakat henüz limitin yarısına bile yaklaşamamışken CPU kısıtlamasına uğruyor. Çok garip değil mi? İşler giderek garipleşiyor.
Bu grafikler doğrultusunda durumu biraz özetlersek:
- Birçok pod işlemleri sırasında daha fazla CPU kaynağına ihtiyaç duyuyor ama CPU limitlerine takıldığı için kısıtlanıyor. Bu da o podların düşük performans altında çalışmalarına sebep oluyor.
- Ortamda boşta olan CPU kaynağı olmasına rağmen limitler sebebiyle kullanılamıyor ve cluster efficiency değeri düşük kalıyor.
- Bazı podlar ise limitlere yaklaşamasalar bile sırf limit değerleri tanımlandıkları için yine bir kısıtlamaya maruz kalıyorlar. Bu çok ilginç ama bu konuda Linux kernel kaynaklı birçok issue (örnekler issuelardan biri, ayrıca yazılmış ayrı bir makale) mevcut. Üstelik bir kernel versiyonunda fixlenmiş olsa bile başka bir versiyonda yine görünüyor olmalı ki biz güncel bir versiyon kullanmamıza rağmen yukarıda resimde olduğu gibi bu durumu gözlemledik.
Öyleyse hadi CPU limitlerini kaldıralım!
Tüm CPU Limitlerini Kaldırmak
Tüm CPU limitlerini kaldırmak kulağa çok sert gelse dahi aslında şimdiye kadar gözlemlediklerimize baktığımızda verimli olacak gibi duruyor. Fakat podların request değerlerini mutlaka doğru ayarlamalıyız ki yetersiz kaynak sebebiyle ayağa kalkamayan podumuz olmasın.
CPU limitlerini kaldırdıktan hemen sonra, tüm CPU kısıtlamaları bir anda ortadan kalktı. Bakın işte grafiğimiz:
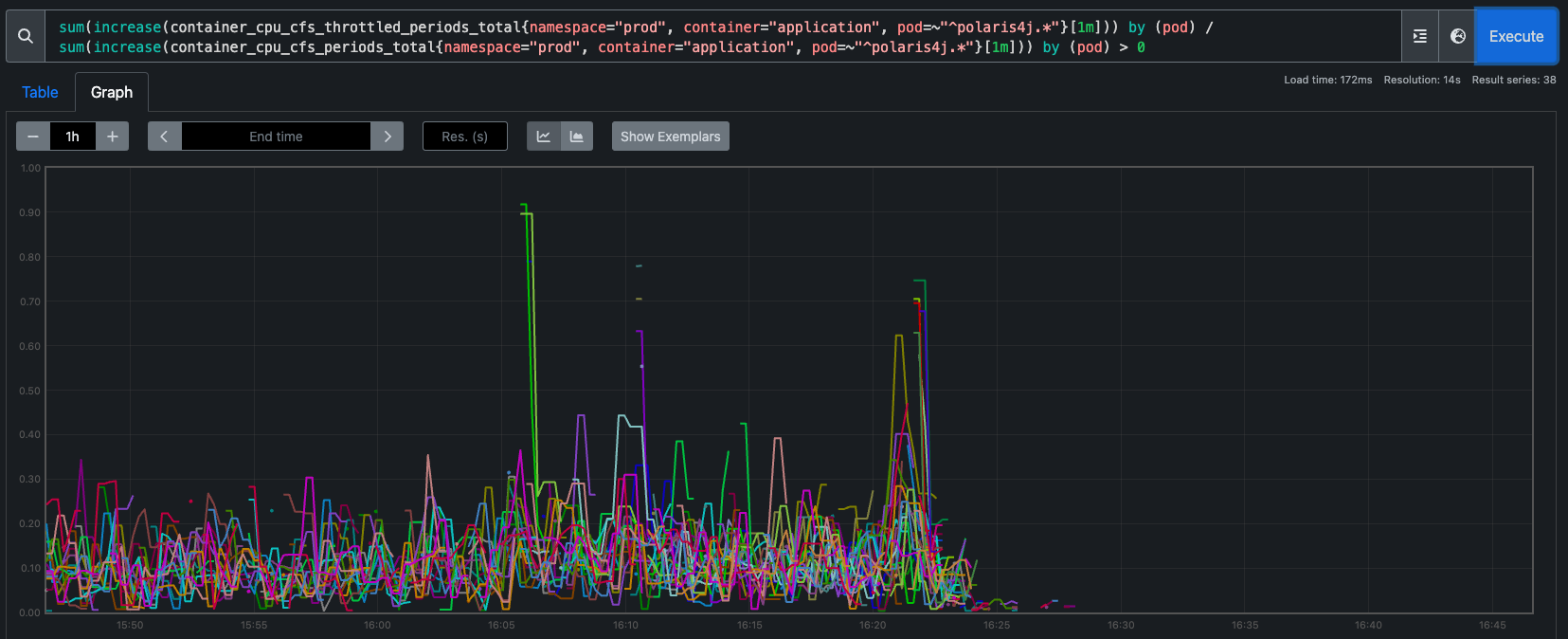
Bu sonuç olarak şu demek:
- Podların request değerleri kadar CPU alacakları Kubernetes tarafından garantileniyor. Böylece CPU kaynaklarımız bitse bile uygulamalar sorunsuz çalışmaya devam ediyor.
- Podlar iş yükü çoğaldıklarında ve daha çok CPU kaynağına ihtiyaç duyduklarında boşta duran CPU kaynaklarına rahatça erişebiliyor.
- Herhangi bir kısıtlamaya ve düşük CPU altında çalışmaya mahkum kalmayan podlar daha performanslı çalışıyor.
Peki başta benimde aklımda olan o soruya gelelim. Dezavantajı ne olabilir?
CPU Limitlerinini Kaldırmaya Dair Endişeler
Bu işe girişmeden önce ve yaptıktan sonra bile aklımda olan bir endişe vardı. Ya uygulamalar yanlış tasarlanmış bir loop veya algoritma sebebiyle podlarının CPU tüketimini sürekli artırırsa?
Normalde limitler varken bu önemsiz bir detaydı. Fakat bir pod bir anda ortamdaki tüm CPU kaynaklarını tüketmeye başlarsa ne olacak?
Bu aslında tüm podlarımız için mantıklı bir request değeri ararken de bir yandan kontrol ettiğimiz bir senaryoydu. Limitler olduğu için de denemeden cevabını bulamayacağımız bir soruydu aslında.
En kötü senaryoyu düşündüğümüzde şunlar olabilirdi:
- Bir pod, üzerindeki node'un tüm CPU kaynaklarını tüketecek
- Node CPU sorunu sebebiyle cevap veremeyecek bir hale gelecek ve clusterdan kopacak (NotReady durumu gibi)
Buna cevabımız ise:
- Birkaç pod bu ihtimali yaşatacak diye neden geri kalan binlerce podu kısıtlayıp performanslarını düşürelim?
- Bir pod request değerinin belli bir katını geçtiğinde alarm üretebiliriz. Örneğin bir hafta boyunca ortalama 0.5core kullanmış ve bizimde bu sebeple requestini 0.75 belirlediğimiz bir pod, bir anda 2 core kullanmaya başlarsa bir anomali var demektir. Bu da
usage > request x 2benzeri bir alarm ile hemen bizi haberdar edecektir. Bunun için aşağıdaki promql sorgusunu örnek alabilirsiniz. Bu sorguyla CPU kullanımı, request değerini %60 aşan podları bulabiliyoruz.
(max(irate(container_cpu_usage_seconds_total{container="application"}[2m])) by (pod) > max(kube_pod_container_resource_requests{container="application", resource="cpu"}) by (pod)) > 0.6- Denemek oldukça eğlenceli ve heyecanlı olacak :)
Biz bunları düşündüğümüzde tüm limitleri kaldırdık ve clusterı gözlemlemeye başladık. Bir gelişme oldukça buradan yazmaya devam edeceğim. Sizinde yorumlarınız varsa aşağıdaki yorum alanını kullanabilirsiniz.
[GÜNCELLEME 1 - 19 Nisan]
Podlarımızın CPU limitlerini kaldırmamızın üstünden bir ay geçti. Tüm bu süre boyunca sadece bir kere bir pod anomali yaşadı ve CPU usage değeri bir anda çok yükseldi.
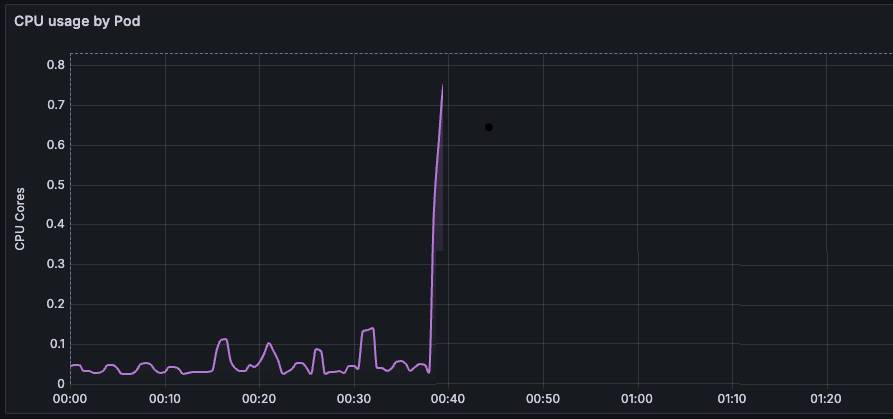
Tabi daha çok yeterli kaynağımız olmasından ve alarm sonucu ilgili podu kill etmemiz sebebinden hiçbir sorun yaşamadık. Ve şu an gidişattan oldukça memnunuz.